Client: getsphere.com
Industry: Policy & compliance
Coverage & Scale: ~4.5k local/regional news domains
Engagement: Build → handoff; client now runs ops
Stack: Python, Scrapy, Redis, PostgreSQL, newspaper3k, AWS S3, Redash, Slack
Polite by design: robots.txt respected on every source
Project Snapshot
Goal: Build a reliable stream of local news for a RAG dataset, delivered every morning.
What we built: Hybrid discovery (RSS + sitemaps + landing‑page scans) → parsing articles to a clean schema → storage (PostgreSQL + S3) → Redash dashboards for metrics visibility → daily Slack summaries & alerts.
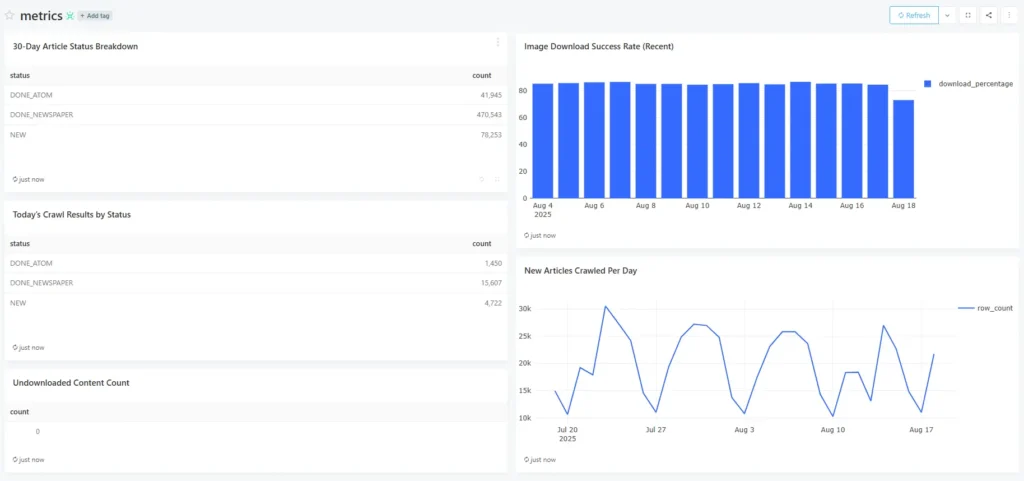
Results (top numbers):
- Volume: 10k-31k new articles/day.
- Last 30 days processed: ≈580k articles
- Freshness SLO: 100% of yesterday’s articles available by morning.
- Image URLs captured: ~85-88% recent average with alerting on dips.
Context & Scope
Unify discovery (RSS, sitemaps, landing-page scans), standardize articles into a consistent schema, store dataset in a PostgreSQL and copy it to S3. Surface ops metrics in Redash with daily Slack summaries. Theme-agnostic: switch topics by updating sources and filters.
What We Built
- Discovery coverage:
- RSS reader our go-to when available
- Sitemap scanner to sweep structured listings
- Landing‑page checker (load front page and go in depth → capture all article links → diff for new URLs)
- Parsing & normalization: newspaper3k turns messy HTML into a standard schema (headline, body, author, date, image URLs).
- Storage: PostgreSQL + copy to S3 for easy RAG dataset upload.
- Monitoring: Redash dashboards on Postgres; daily Slack digest + anomaly alerts (volume spikes/drops, image %).
Outcomes for the Client
- An analysis‑ready local news dataset that refreshes daily.
- Consistent schema and predictable volume, enabling downstream labeling and retrieval.
- Ops visibility via Redash charts and Slack alerts – no manual checking.
Reliability & Ops (how it stays healthy)
- Source failover: RSS → sitemap → landing‑page scan.
- Retries/backoff and shardable Scrapy workers.
- Alert‑driven workflow: drops in daily volume or image coverage trigger Slack summaries with Redash links.
Tooling choice & costs insights
- We chose newspaper3k across all articles for now; occasional inaccuracies are outweighed by speed and coverage.
- Going Zyte AP only would land around $3,000-$4,500/month. Our newspaper3k servers cost ~$100/month at today’s scale.
- Hybrid option is available: keep newspaper3k by default and route the hardest sources through Zyte when it adds clear value.